Predykcja awarii chłodzenia — co mówią trend temperatury i poboru mocy
Predykcja awarii chłodzenia bez algorytmów: jak trend temperatury i poboru mocy zdradza słabnący agregat na tygodnie przed awarią i jak ustawić progi.
Zespół Nextriv4 min czytania

Predykcja awarii chłodzenia brzmi jak projekt dla zespołu data science: modele, algorytmy, budżet. W praktyce zdecydowana większość awarii sprężarek, agregatów i klimatyzatorów nie przychodzi nagle — urządzenie słabnie tygodniami, a objawy zapisują się w dwóch przebiegach, które potrafi mierzyć każdy: temperaturze i poborze mocy. Wystarczy je rejestrować, patrzeć na trend zamiast na pojedynczą wartość i ustawić progi ostrzegawcze sporo poniżej poziomu katastrofy. Pokazujemy, jak to zrobić — bez linijki kodu i bez wróżenia z fusów.
Awaria chłodzenia rzadko jest nagła
Z perspektywy hali czy sklepu awaria wygląda na nagłą: wczoraj działało, dziś towar się rozmraża. Z perspektywy fizyki to finał procesu, który trwał tygodniami:
- Zabrudzony skraplacz oddaje ciepło coraz gorzej — sprężarka pracuje dłużej i ciężej, by utrzymać tę samą temperaturę.
- Ubytek czynnika chłodniczego wydłuża cykle pracy i stopniowo podnosi temperaturę w komorze, choć nastawy się nie zmieniły.
- Zużywające się łożyska wentylatorów i sprężarki zwiększają opory — a więc i pobór prądu — na długo zanim cokolwiek zacznie hałasować.
- Oblodzony parownik dławi wymianę ciepła: urządzenie pracuje niemal bez przerwy, a chłodzi coraz słabiej.
Każdy z tych mechanizmów zostawia ślad w danych na długo przed dniem, w którym dzwoni telefon. Problem w tym, że ślad jest subtelny: pół stopnia tu, kilka procent mocy tam. Pojedynczy odczyt wygląda zupełnie normalnie — dopiero trend zdradza kierunek.
Predykcja awarii chłodzenia w praktyce: dwa trendy zamiast wróżenia
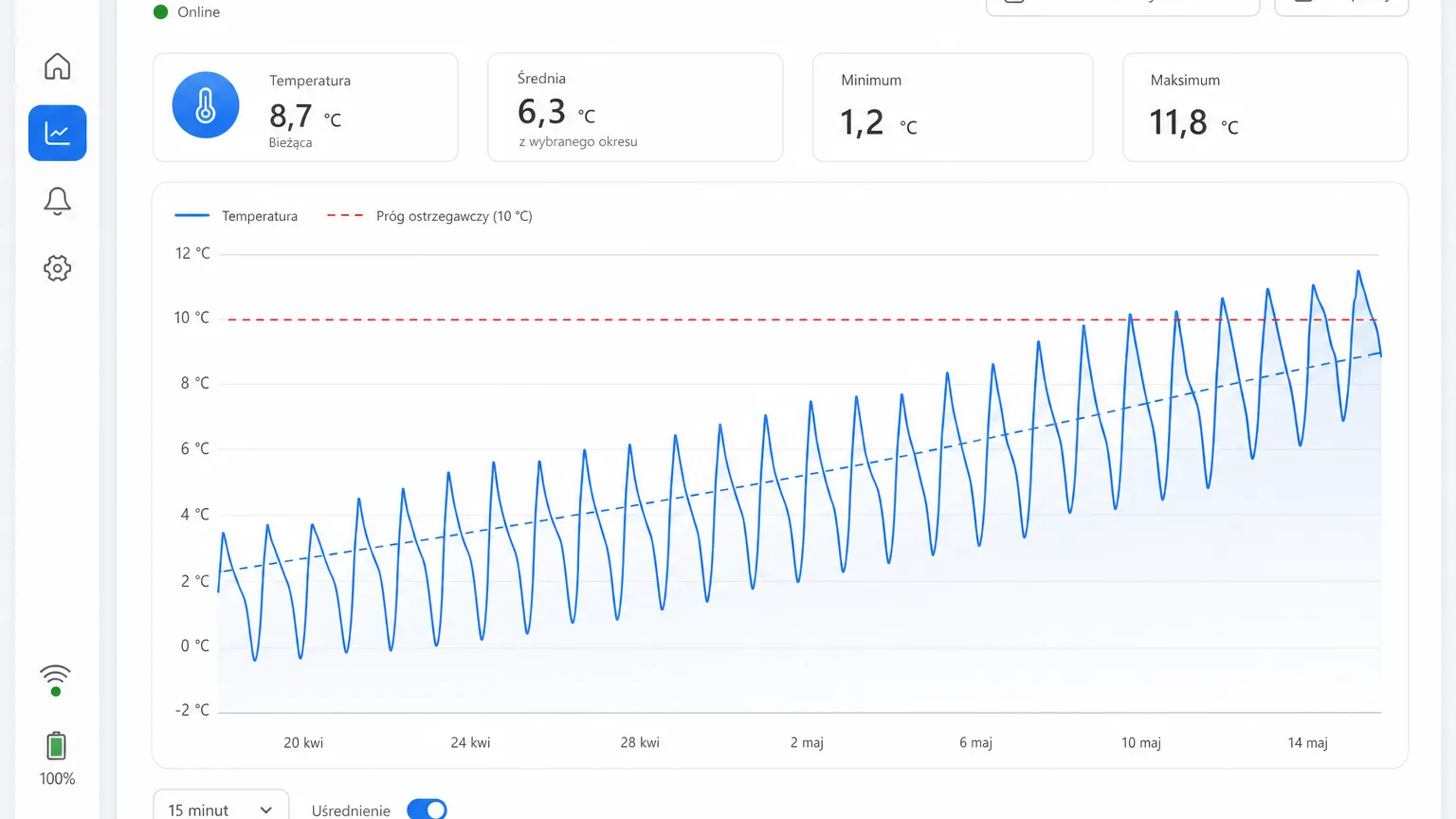
Trend temperatury — nie wartość, lecz kształt
Na wykresie temperatury słabnące chłodzenie widać w trzech sygnałach:
- Dryf średniej. Średnia temperatura komory czy strefy pełznie w górę o ułamki stopnia tygodniowo przy niezmienionych nastawach. W bieżącym podglądzie niewidoczne, na wykresie miesiąca — oczywiste.
- Wydłużający się powrót. Po odszranianiu, dostawie albo otwarciu drzwi temperatura wraca do zadanej coraz dłużej. Czas powrotu to najczulszy wskaźnik topniejącego zapasu mocy chłodniczej.
- Rosnąca amplituda cykli. „Zęby piły" na wykresie robią się wyższe i rzadsze — urządzenie traci zdolność szybkiego zbicia temperatury.
Trend poboru mocy — EKG agregatu
Pomiar elektryczny mówi o stanie maszyny to, czego temperatura jeszcze nie pokazuje. Rosnąca moc przy tej samej temperaturze zadanej oznacza spadającą sprawność — klasyczny objaw brudnego skraplacza. Rosnące dzienne kWh przy niezmienionym obciążeniu mówią, że urządzenie pracuje coraz dłużej, by osiągnąć ten sam efekt. A skok prądu ponad próg to już nie predykcja, lecz alarm przeciążenia — ostatni dzwonek przed zadziałaniem zabezpieczeń.
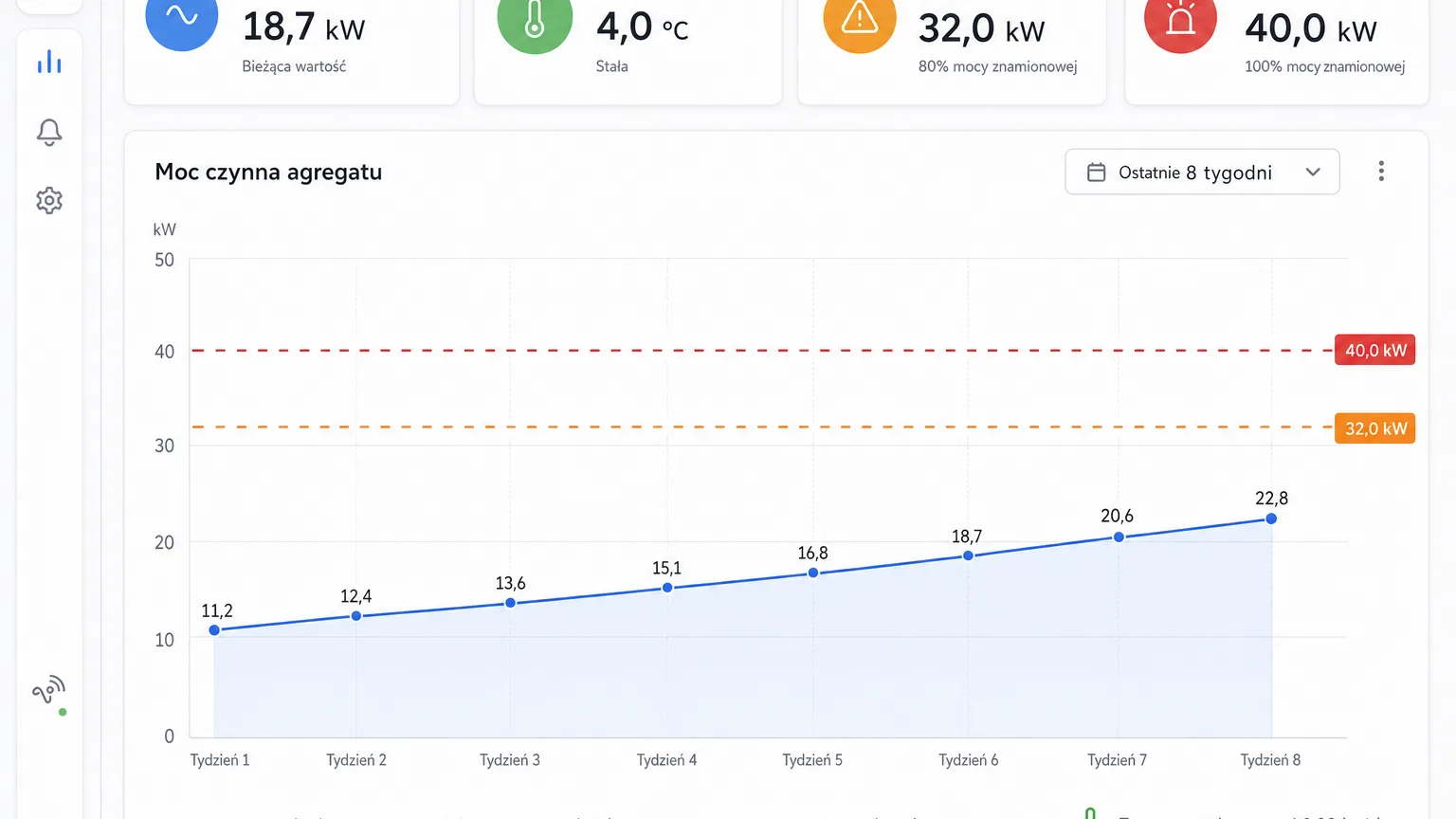
Najwięcej mówi zestawienie obu przebiegów na jednym wykresie. Temperatura stabilna przy rosnącej mocy oznacza, że urządzenie nadrabia mocą ubytek sprawności; gdy zaczyna rosnąć także temperatura — zapas właśnie się skończył.
Czym to zmierzyć: punkt pomiarowy w godzinę
Pobór mocy urządzeń wpinanych do gniazdka — witryny chłodniczej, lodówki laboratoryjnej, klimatyzatora przenośnego — mierzy się bez elektryka. Inteligentne gniazdo pośrednie rejestruje napięcie, prąd, moc czynną, współczynnik mocy i skumulowane kWh osobno dla każdego odbiornika, a do tego alarmuje o przeciążeniu i zaniku zasilania.

Tam, gdzie trzeba zmierzyć samą maszynę — łożysko, sprężarkę, instalację wody lodowej — pracuje przemysłowa sonda platynowa Nextriv Probe PT100: dokładność ±0,5 °C, nadajnik IP67 odporny na wibracje, bateria na lata pracy i lokalny bufor pomiarów z retransmisją po przerwie w łączności, żeby w trendzie nie było dziur.

Oba urządzenia łączą się z platformą łącznością radiową dalekiego zasięgu, której sygnał przechodzi przez ściany hal i komór — bez okablowania. Automatyczne wykrywanie zgłasza nowe urządzenie w platformie w 30–180 sekund od włączenia.
Cztery progi: ostrzegawczy to twoja predykcja
W Nextriv każda metryka ma cztery progi: ostrzegawczy i krytyczny, dolny i górny. To rozróżnienie jest sednem całej metody. Próg krytyczny chroni towar i sprzęt — to reakcja „tu i teraz". Próg ostrzegawczy, ustawiony tuż nad normalnym zakresem pracy, wyłapuje dryf — i to on pełni rolę predykcji.
Praktyczna recepta: po pierwszym miesiącu pomiarów odczytaj z wykresów normalny zakres temperatury i poboru mocy, a progi ostrzegawcze ustaw 10–15% powyżej typowych szczytów. Ich przekroczenie nie oznacza jeszcze awarii — oznacza zlecenie przeglądu: czyszczenie skraplacza, kontrola czynnika, odszranianie. Tani serwis planowy zamiast drogiego awaryjnego.
Każde przekroczenie otwiera zdarzenie z unikalnym kodem (np. ALM-7C2F19) i poziomem ważności, a deduplikacja pilnuje, by jeden problem był jednym zdarzeniem. Powiadomienie idzie kanałem, który zespół naprawdę czyta — e-mail, SMS, push, MS Teams, Discord lub alarm dźwiękowy w aplikacji; integracja webhooks przekaże zdarzenie wprost do systemu zgłoszeń utrzymania ruchu — a eskalacje dopilnują, by alert bez potwierdzenia trafił poziom wyżej. I jeszcze jedno: najgorszy trend to brak danych. Czujnik, który zamilknie na dwukrotność swojego interwału raportowania, automatycznie dostaje status offline — bo cisza też bywa objawem.
Historia, która zamienia trend w prognozę
Tygodniowy wykres pokazuje dryf; roczny daje kontekst. Lipcowy wzrost poboru mocy może być degradacją — albo po prostu latem. Rozstrzyga porównanie z analogicznym okresem: ta sama pora roku, podobne obciążenie, wyraźnie wyższa moc — sprawność spada. Plan bezpłatny Nextriv przechowuje surowe pomiary przez 365 dni, płatny przez 1825 dni (5 lat) — wystarczająco, by porównywać sezon z sezonem przez cały cykl życia urządzenia.
Na pulpicie zestawisz oba przebiegi na jednym wykresie wieloseryjnym, kafelek porównania czujników pokaże, która z pięciu witryn odstaje od pozostałych, a czujniki wirtualne wyliczą np. średnią temperaturę strefy jako osobną metrykę. Raporty PDF i eksporty XLSX/CSV zamieniają trend w twardy argument na przeglądzie technicznym.
Ta sama metoda działa wszędzie tam, gdzie chłodzenie jest krytyczne: w serwerowni i data center, gdzie rosnący pobór klimatyzacji precyzyjnej zapowiada hot spoty, oraz w zakładzie produkcyjnym, gdzie agregat, chłodnica maszyny czy komora przechowalnicza rzadko psują się w godzinach pracy serwisu.
Zacznij od najdroższej awarii
Nie potrzebujesz półrocznego programu pilotażowego. Wybierz urządzenie, którego awaria zabolałaby najbardziej, wepnij pomiar mocy, dołóż sondę temperatury i daj danym miesiąc na pokazanie normy. Plan bezpłatny — 10 czujników, jedna bramka, rok historii — wystarcza, by zacząć bez żadnej subskrypcji.
Porównaj plany w cenniku albo umów prezentację — pokażemy na żywych danych, jak słabnący agregat wygląda na wykresie, zanim stanie się tytułem zgłoszenia serwisowego.


